前言 很高兴遇见你~
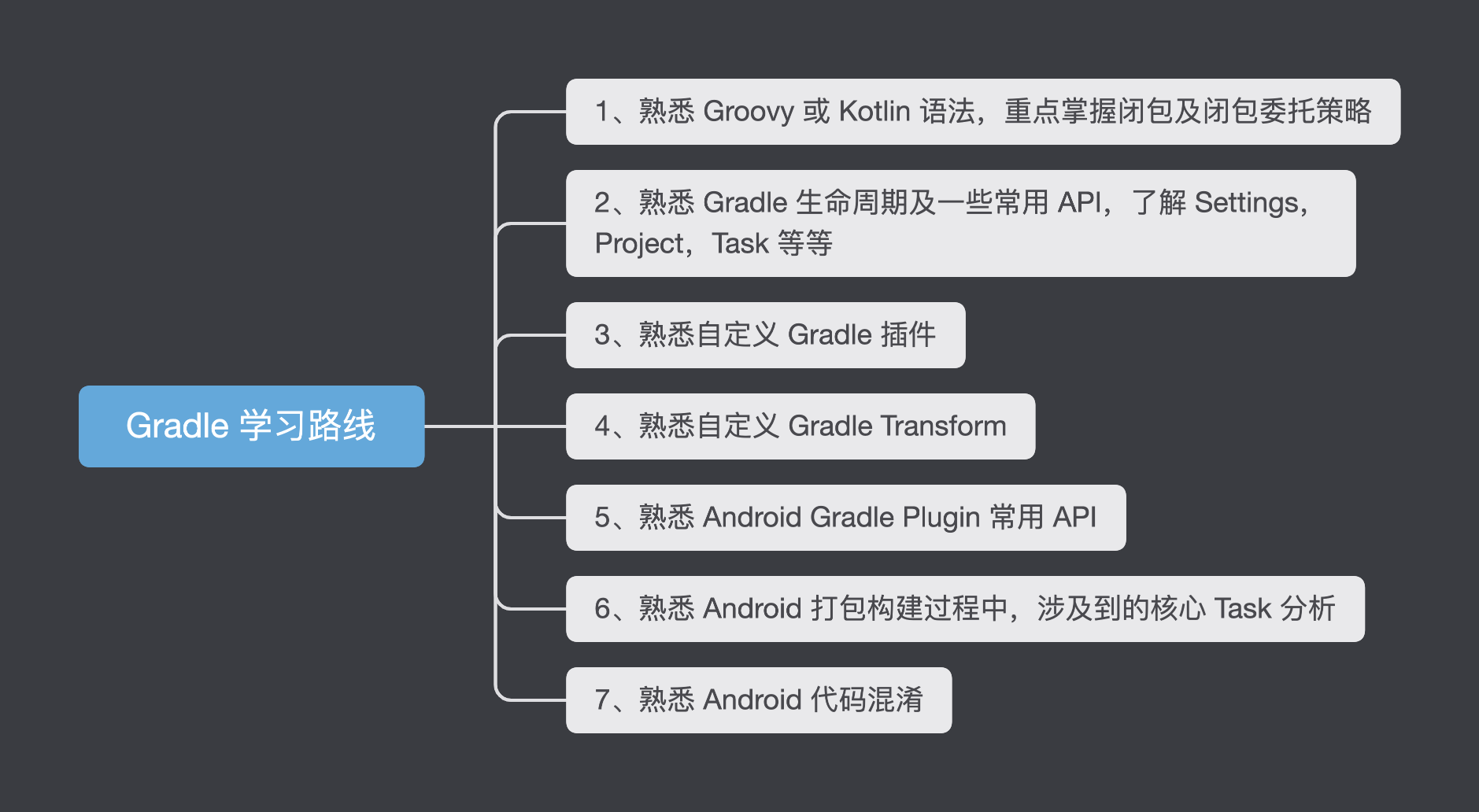
关于 Gradle 学习,我所理解的流程如下图:
在本系列的前 4 篇文章中,我们了解了:
1、Groovy 语法
2、Gradle 常用 api,生命周期及 hook 点,Task 定义,依赖与挂接到构建流程的基本操作
3、自定义 Gradle 插件及实战演练
还不清楚上面这些知识点的朋友,建议先去阅读我创建的Gradle 学习专栏
下面我抛出一些问题 ,大家可以思考下🤔:
1、为了对 app 性能做一个全面的评估,我们需要做 UI,内存,网络等方面的性能监控,如何做?
2、发现某个第三方库有 bug ,用起来不爽,但又不想拿它的源码修改在重新编译,有什么好的办法?
3、我想在不修改源码的情况下,统计某个方法的耗时,对某个方法做埋点,怎么做?
为了实现上面的想法,可能我们最开始的第一反应:是能否通过 APT,反射,动态代理来实现?但是想来想去,这些方案都不能很好的满足上面的需求,而且,有些问题不能从 Java 源文件入手,我们应该从 Class 字节码文件寻找突破口
JVM 平台上,修改、生成字节码无处不在,从 ORM 框架(如 Hibernate, MyBatis)到 Mock 框架(如 Mockito),再到 Java Web 中的常⻘树 Spring 家族,再到新兴的 JVM 语言 Kotlin 编译器,还有大名鼎鼎的 cglib,都有字节码的身影
字节码相关技术的强大之处自然不用多说,而在 Android 开发中,无论是使用 Java 开发还是 Kotlin 开发,都是 JVM 平台的语言,所以如果我们在 Android 开发中,使用字节码技术做一下 hack,还可以天然地兼容 Java 和 Kotlin 语言
现在目的很明确,我们就是要通过修改字节码的技术去解决上面的问题,那这和我们今天要讲的 Gradle Transform 有什么关系呢?
接下来我们就进入 Gradle Transform 的学习
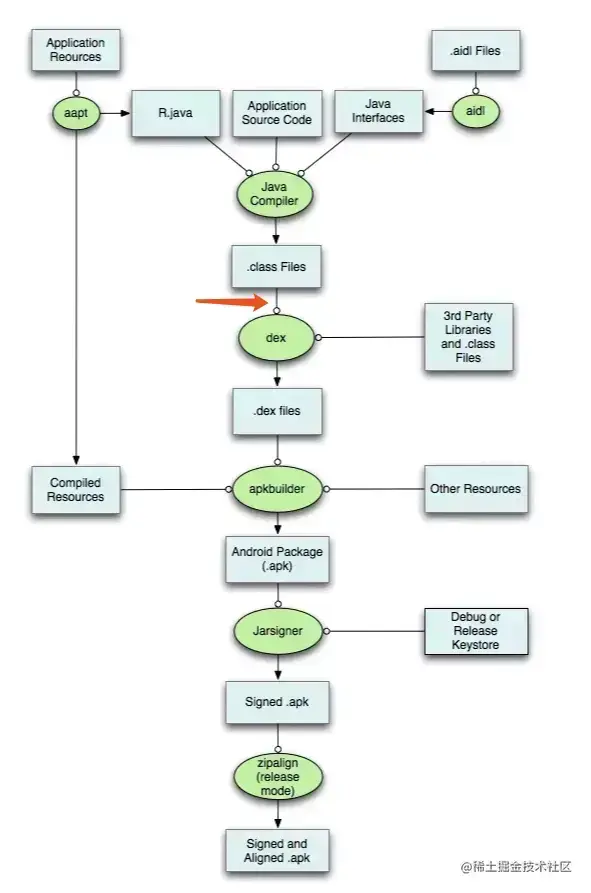
Gradle Transform 是 AGP(Android Gradle Plugin )1.5 引入的特性,主要用于在 Android 构建过程中,在 Class→Dex 这个节点修改 Class 字节码。利用 Transform API,我们可以拿到所有参与构建的 Class 文件,借助 Javassist 或 ASM 等字节码编辑工具进行修改,插入自定义逻辑
一图胜千言:
虽然在 AGP 7.0 中 Transform 被标记为废弃了,但还可以使用,并不妨碍我们的学习,但是会在 AGP 8.0 中移除。
后续文章我也会讲如何适配使用新的 Api 去进行 Transform 的替换,因此大家不用担心🍺
先不管细节,咱们直接实现一个自定义 Gradle Transform 在说,按照下面的步骤,保姆式教程
实现一个 Transform 需要先创建 Gradle 插件,大致流程:自定义 Gradle 插件 -> 自定义 Transform -> 注册 Transform
如果你了解自定义 Gradle 插件,那么自定义 Gradle Transform 将会变得非常简单,不了解的去看我的这篇文章Gradle 系列 (三)、Gradle 插件开发
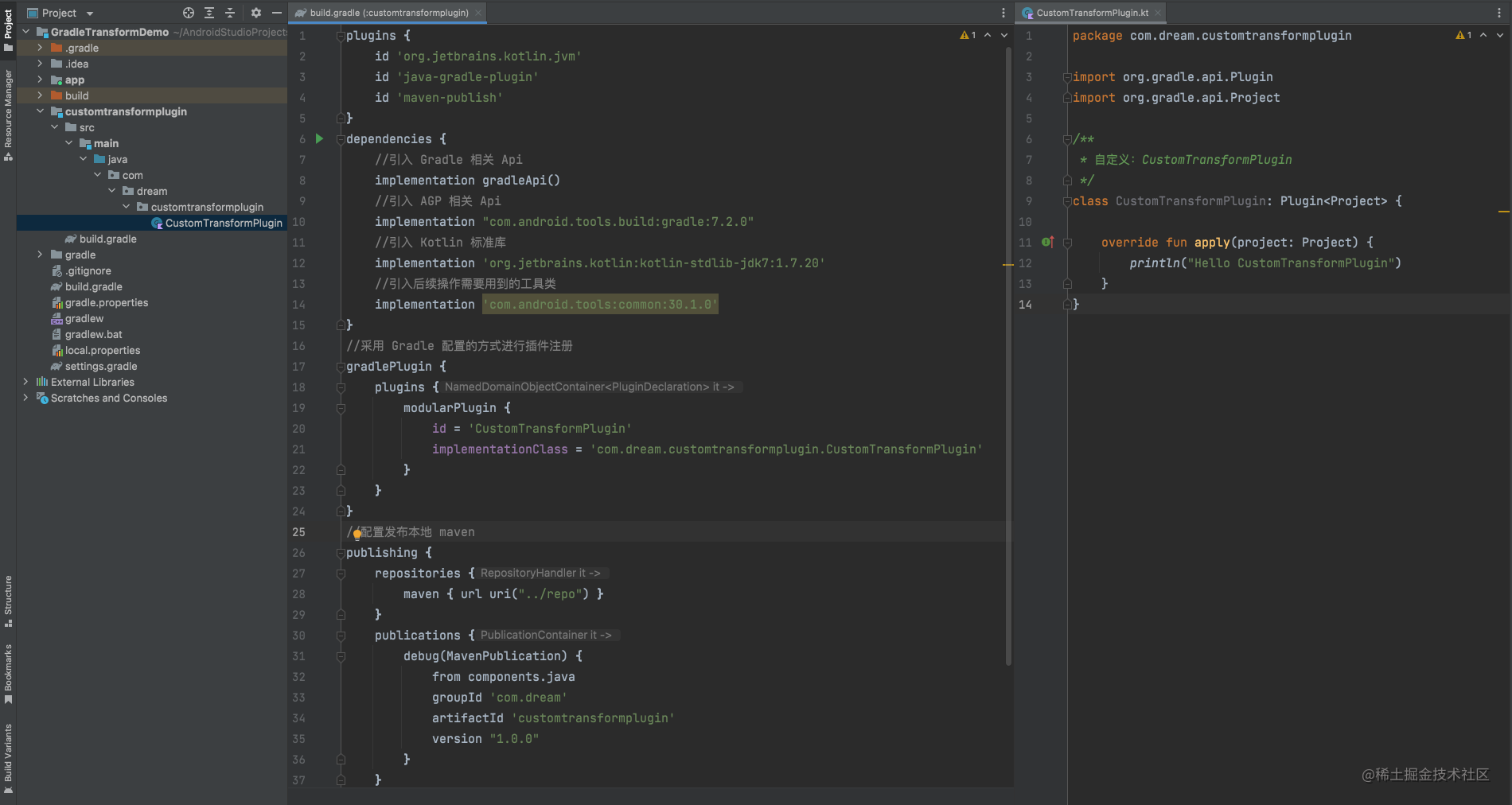
首先给大家看一眼我项目初始化的一个配置:
可以看到:
1、AGP 版本:7.2.0
2、Gradle 版本:7.4
我的 AndroidStudio 版本:Dolphin | 2021.3.1
大家需要对应好 AndroidStudio 版本所需的 AGP 版本,AGP 版本所需的 Gradle 版本,否则会出现兼容性和各种未知的问题,对应关系可以去官网 查询
另外大家会发现,AGP 7.x 中 settings.gradle 和根 build.gradle 文件使用了一种新的配置方式,建议改回原来的配置方式,坑少😄:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 "GradleTransformDemo" ':app' "1.7.20" "com.android.tools.build:gradle:7.2.0" "org.jetbrains.kotlin:kotlin-gradle-plugin:1.7.20" type: Delete) {
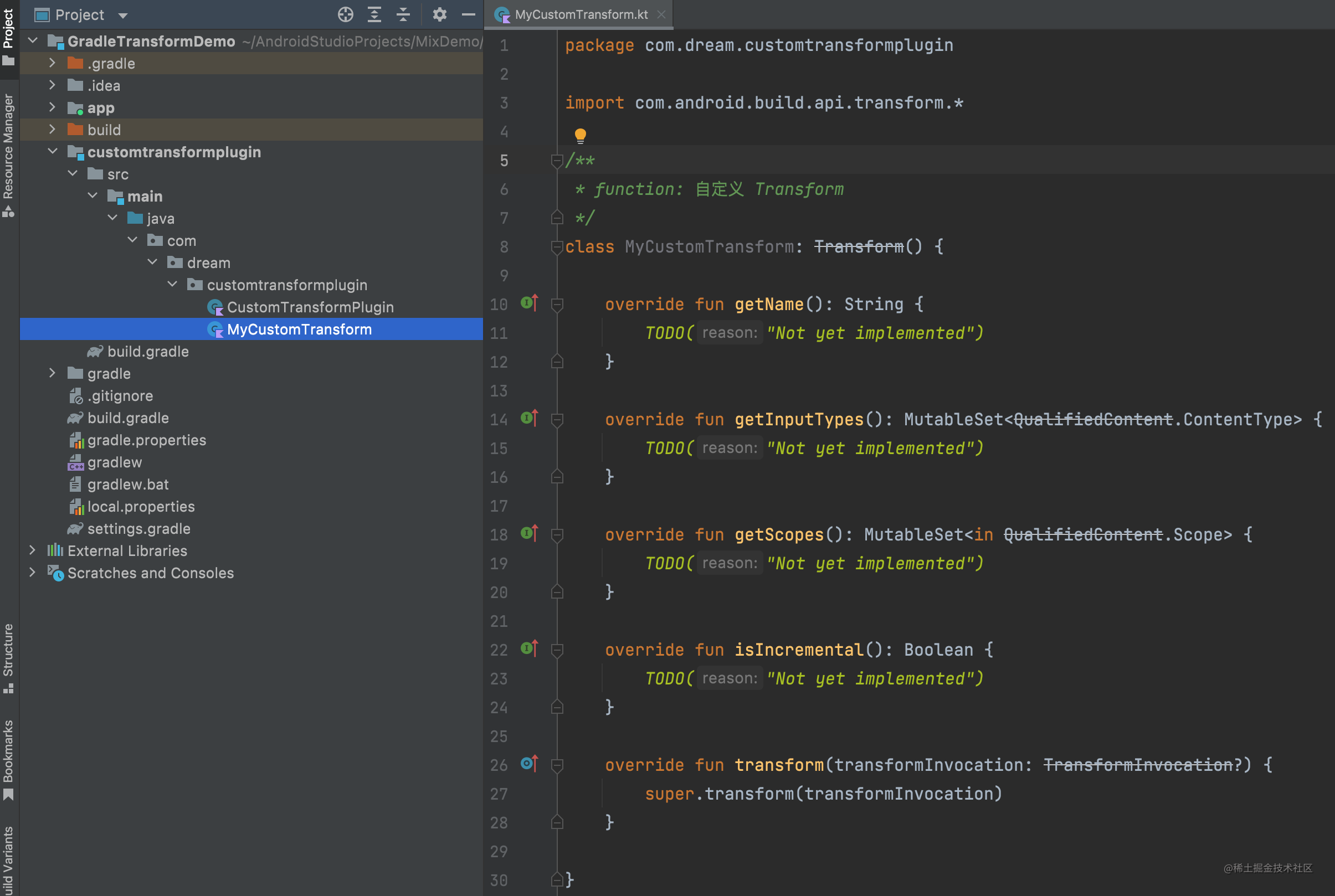
2.1、自定义 Gradle 插件 创建 Gradle 插件 Module:customtransformplugin,初始代码如下图:
注意 :此插件我是使用 Kotlin 编写的,和之前 Groovy 编写插件的区别:
1、Kotlin 编写的插件可以直接写在 src/main/java目录下,另外 AndroidStudio 对 Kotlin 多了很多扩展支持,编写效率高
2、 Groovy 编写插件需要写在src/main/groovy目录下
Transform 相关 Api 需要如下依赖:
1 implementation "com.android.tools.build:gradle-api:7.2.0"
但是上述并没有引入,是因为 AGP 相关 Api 依赖了它,根据依赖传递的特性,因此我们可以引用到 Transform 相关 Api
初始代码如下图:
接着对其进行简单的修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 package com.dream.customtransformpluginimport com.android.build.api.transform.*import com.android.build.gradle.internal .pipeline.TransformManagerimport com.android.utils.FileUtilsclass MyCustomTransform : Transform () {override fun getName () return "ErdaiTransform" override fun getInputTypes () return TransformManager.CONTENT_CLASSoverride fun getScopes () in QualifiedContent.Scope> {return TransformManager.SCOPE_FULL_PROJECToverride fun isIncremental () Boolean {return false override fun transform (transformInvocation: TransformInvocation ?) val dest = transformInvocation.outputProvider.getContentLocation(val dest = transformInvocation.outputProvider.getContentLocation(fun printLog () "******************************************************************************" )"****** ******" )"****** 欢迎使用 ErdaiTransform 编译插件 ******" )"****** ******" )"******************************************************************************" )
在 CustomTransformPlugin 中对 TransForm 进行注册,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class CustomTransformPlugin : Plugin <Project > {override fun apply (project: Project ) "Hello CustomTransformPlugin" )val androidExtension = project.extensions.getByType(AppExtension::class .java)
ok,经过上面三步,一个最简单的自定义 Gradle Transform 插件已经完成了
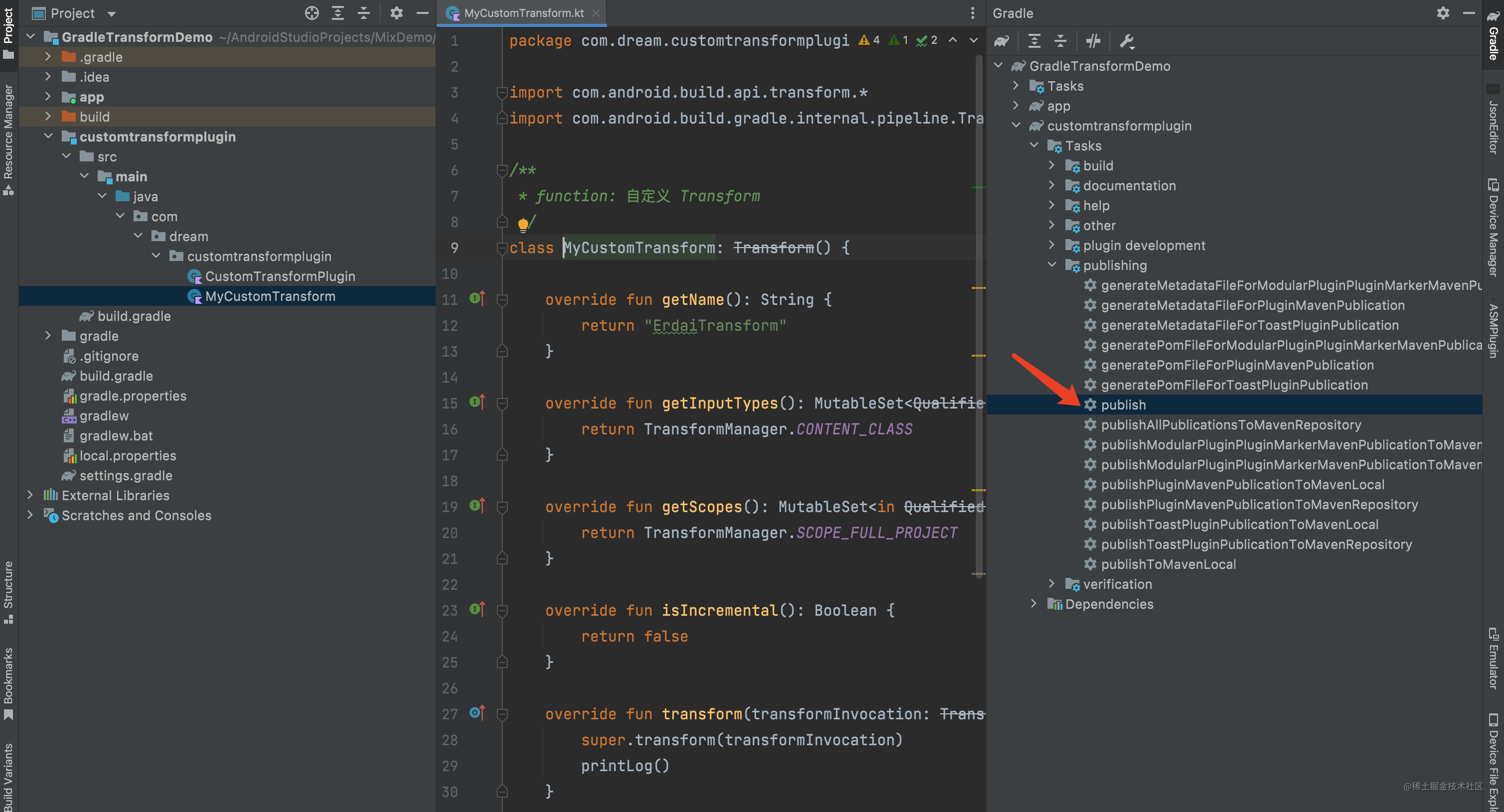
2.4、上传插件到本地仓库 点击 publish进行发布
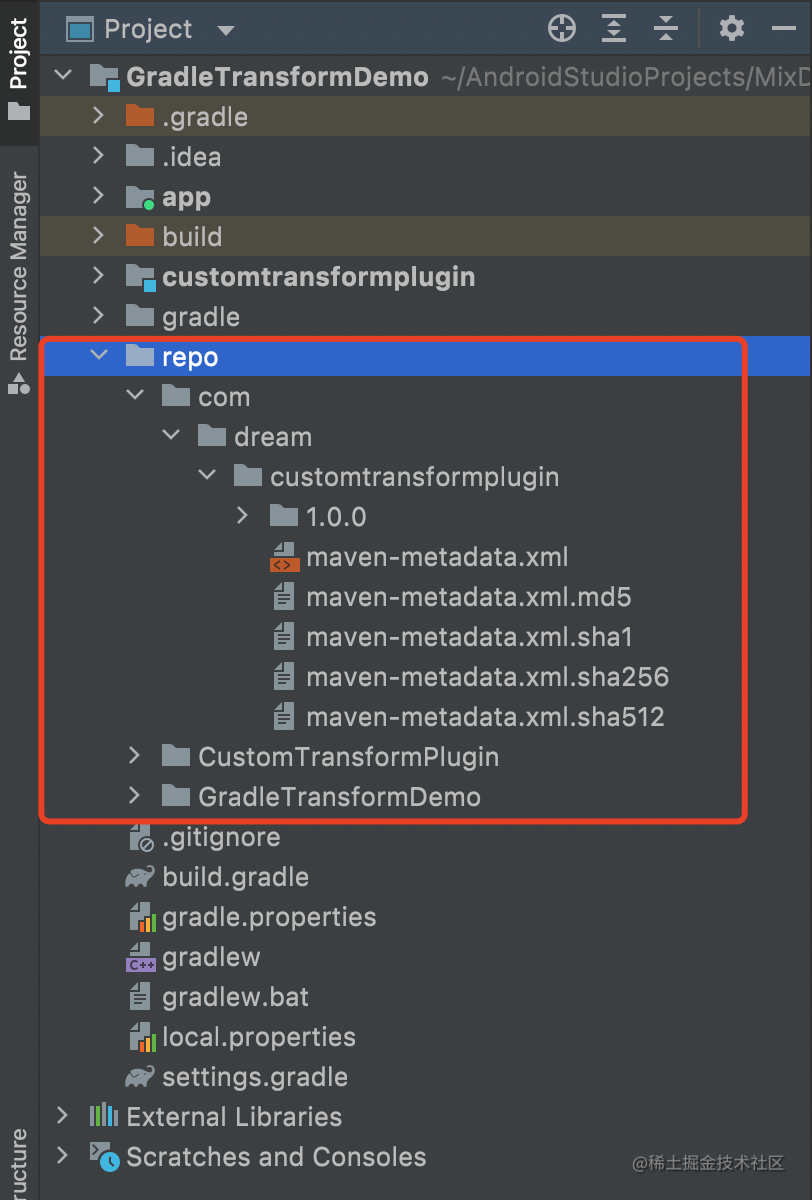
如果你的项目多了如下内容,则证明发布成功了
2.5、效果验证 在根 build.gradle 进行插件依赖:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 buildscript {'repo' )"com.dream:customtransformplugin:1.0.0"
在 app 的 build.gradle 应用插件:
1 2 3 4 5 plugins {'CustomTransformPlugin'
同步一下项目,运行 app
配置阶段打印如下图:
执行阶段打印如下图:
这样我们一个最简单的自定义 Gradle Transform 就完成了
另外需要注意 :当你对自定义 Gradle Transform 做修改后想看效果,务必升级插件的版本,重新发布,然后在根 build.gradle 中修改为新的版本,同步后在重新运行,否则 Gradle Transform 会不生效
消化一下,接下来我们讲点 Transform 的细节
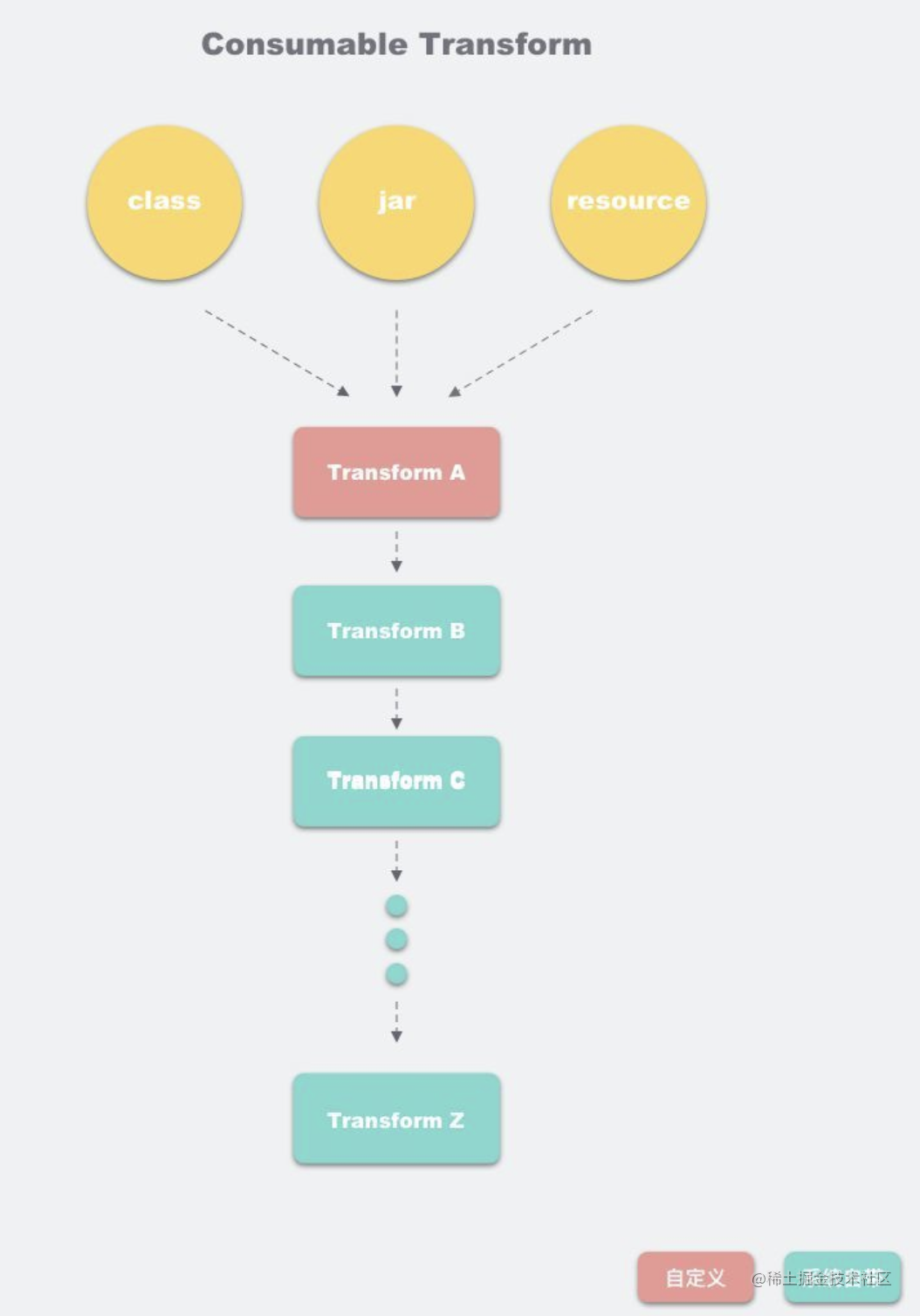
Transform 数据流动主要分为两种:
1、消费型 Transform :数据会输出给下一个 Transform
2、引用型 Transform :数据不会输出给下一个 Transform
如下图:
1、每个 Transform 其实都是一个 Gradle Task,AGP 中的 TaskManager 会将每个 Transform 串连起来
2、第一个 Transform 会接收:
1、来自 Javac 编译的结果
2、拉取到在本地的第三方依赖(jar,aar)
3、resource 资源(这里的 resource 并非 Android 项目中的 res 资源,而是 assets 目录下的资源)
3、这些编译的中间产物,会在 Transform 组成的链条上流动,每个 Transform 节点可以对 Class 进行处理再传递给下一个Transform
4、我们常⻅的混淆,Desugar 等逻辑,它们的实现都是封装在一个个 Transform 中,而我们自定义的 Transform,会插入到这个Transform 链条的最前面
引用型 Transform 会读取上一个 Transform 输入的数据,而不需要输出给下一个Transform,例如 Instant Run 就是通过这种方式,检查两次编译之间的 diff 进行快速运行
ok,了解了 Transform 的数据流动,我们回到自定义 Transform 的初始状态,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class MyCustomTransform : Transform () {override fun getName () return "ErdaiTransform" override fun getInputTypes () return TransformManager.CONTENT_CLASSoverride fun getScopes () in QualifiedContent.Scope> {return TransformManager.SCOPE_FULL_PROJECToverride fun isIncremental () Boolean {return false override fun transform (transformInvocation: TransformInvocation ?) super .transform(transformInvocation)
我们重写了 Transform 的 5 个方法,接下来具体介绍下
3.2、getName 1 2 3 override fun getName () return "ErdaiTransform"
getName 方法主要是获取自定义 Transform 的名称,可以看到它接收的是一个 String 字符串的类型,它的作用:
1、进行 Transform 唯一标识,一个应用内可以有多个 Transform,因此需要一个名称,方便后面调用
2、创建 Transform Task 命名时会用到它
通过源码验证一下,如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @NonNull public <T extends Transform> Optional<TaskProvider<TransformTask>> addTransform(@NonNull TaskFactory taskFactory,@NonNull VariantCreationConfig creationConfig,@NonNull T transform,@Nullable PreConfigAction preConfigAction,@Nullable TaskConfigAction<TransformTask> configAction,@Nullable TaskProviderCallback<TransformTask> providerCallback) {"" );@VisibleForTesting @NonNull @NonNull Transform transform) {100 );"transform" );"And" )));"With" );"For" );return sb.toString();
注意 :方法前后省略了大量代码,我们只看主线流程
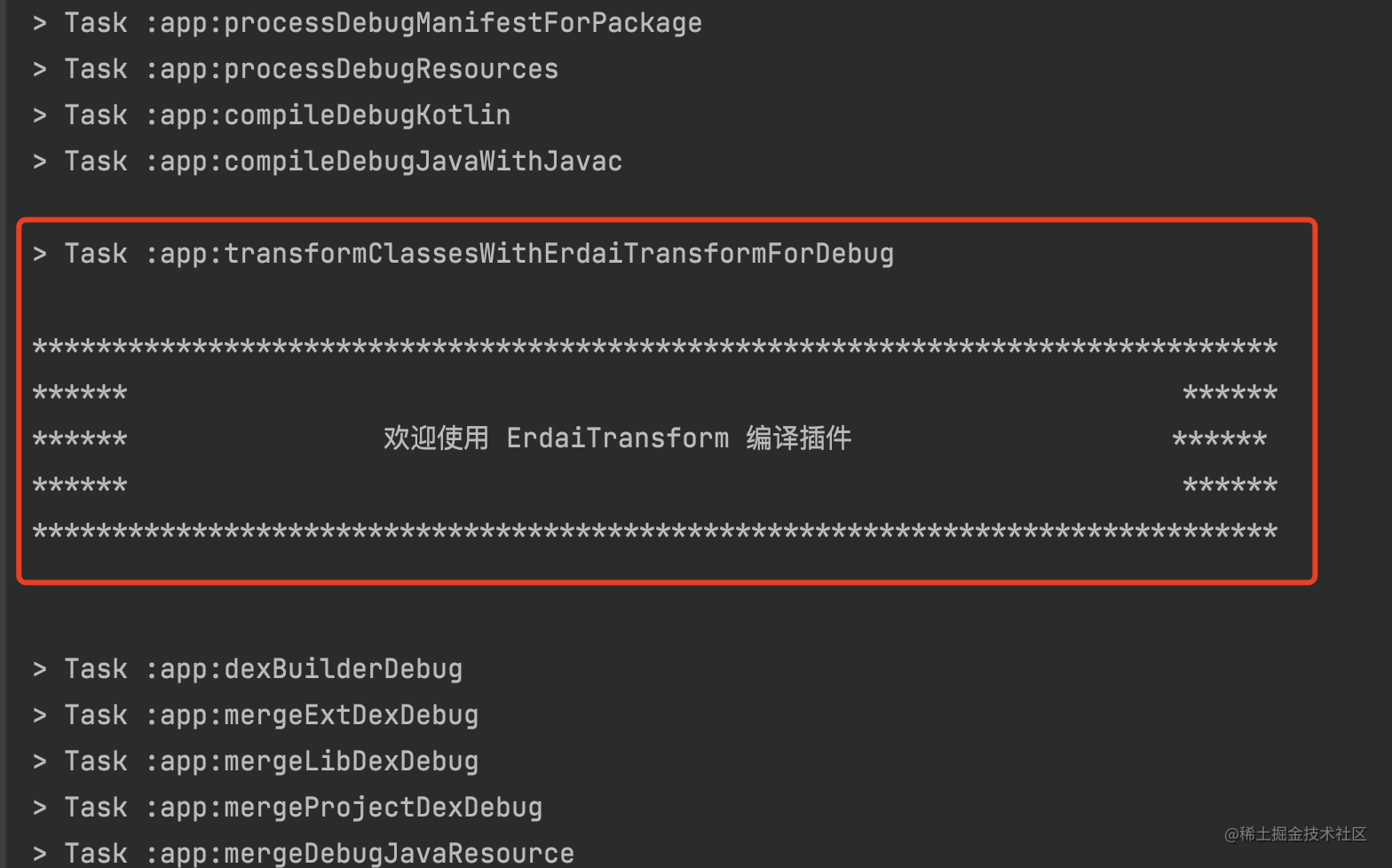
从上面代码,我们可以看到新建的 Transform Task 的命名规则可以理解为:
transform${inputType1.name}And${inputType2.name}With${transform.name}For${variantName}
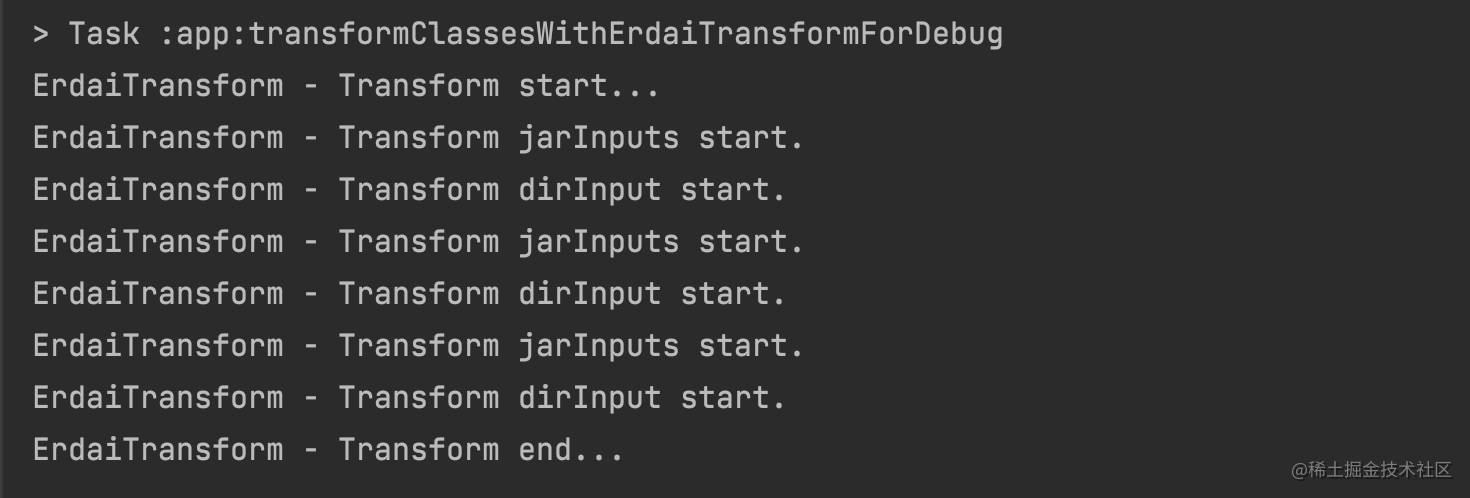
通过我们上面生成的 Transform Task 也可以验证这一点:
1 > Task :app:transformClassesWithErdaiTransformForDebug
1 2 3 override fun getInputTypes () return TransformManager.CONTENT_CLASS
getInputTypes 方法主要用于获取输入类型,可以看到它接收一个 ContentType 的 Set 集合,表示它允许输入多种类型。上述返回值我们使用了 TransformManager 内置的输入类型,我们也可以自定义,如下:
1 2 3 4 override fun getInputTypes () return ImmutableSet.of(QualifiedContent.DefaultContentType.CLASSES)
ContentType 是一个接口,表示输入或输出内容的类型,它有两个实现枚举类 DefaultContentType 和 ExtendedContentType 。但是,我们在自定义 Transform 时只能使用 DefaultContentType 中定义的枚举,即 CLASSES 和 RESOURCES 两种类型,其它类型仅供 AGP 内置的 Transform 使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 enum DefaultContentType implements ContentType {0x01 ),0x02 );public enum ExtendedContentType implements ContentType {0x1000 ),0x2000 ),0x4000 ),0x10000 ),0x40000 ),
自定义 Transform 我们可以在两个位置定义 ContentType:
1、Set getInputTypes(): 指定输入内容类型,允许通过 Set 集合设置输入多种类型
2、Set getOutputTypes(): 指定输出内容类型,默认取 getInputTypes() 的值,允许通过 Set 集合设置输出多种类型
看一眼 TransformManager 给我们内置的 ContentType 集合,常用的是 CONTENT_CLASS :
1 2 3 4 5 6 public static final Set<ContentType> CONTENT_CLASS = ImmutableSet.of(CLASSES);public static final Set<ContentType> CONTENT_JARS = ImmutableSet.of(CLASSES, RESOURCES);public static final Set<ContentType> CONTENT_RESOURCES = ImmutableSet.of(RESOURCES);public static final Set<ContentType> CONTENT_DEX = ImmutableSet.of(ExtendedContentType.DEX);public static final Set<ContentType> CONTENT_DEX_WITH_RESOURCES =
3.4、getScopes 1 2 3 override fun getScopes () in QualifiedContent.Scope> {return TransformManager.SCOPE_FULL_PROJECT
getScopes 方法主要用来定义检索的范围,告诉 Transform 需要处理哪些输入文件,可以看到它接收的是一个 Scope 的 Set 集合。上述返回值我们使用了 TransformManager 内置的 Scope 集合,如果不满足你的需求,你可以自定义,如下:
1 2 3 4 5 6 override fun getScopes () in QualifiedContent.Scope> {return ImmutableSet.of(QualifiedContent.Scope.PROJECT,
Scope 是一个枚举类:
1 2 3 4 5 6 7 8 9 10 11 12 enum Scope implements ScopeType {0x01 ),0x04 ),0x10 ),0x20 ),0x40 ),
自定义 Transform 可以在两个位置定义 Scope:
1、Set getScopes() 消费型输入内容范畴: 此范围的内容会被消费,因此当前 Transform 必须将修改后的内容复制到 Transform 的中间目录中,否则无法将内容传递到下一个 Transform 处理
2、Set getReferencedScopes() 指定引用型输入内容范畴: 默认是空集合,此范围的内容不会被消费,因此不需要复制传递到下一个 Transform,也不允许修改。
看一眼 TransformManager 给我们内置的 Scope 集合,常用的是 SCOPE_FULL_PROJECT 。需要注意,Library 模块注册的 Transform 只能使用 Scope.PROJECT
1 2 public static final Set<ScopeType> PROJECT_ONLY = ImmutableSet.of(Scope.PROJECT);public static final Set<ScopeType> SCOPE_FULL_PROJECT = ImmutableSet.of(Scope.PROJECT, Scope.SUB_PROJECTS, Scope.EXTERNAL_LIBRARIES);
3.5、isIncremental 1 2 3 override fun isIncremental () Boolean {return false
isIncremental 方法主要用于获取是否是增量编译,true:是, false:否。一个自定义 Transform 应该尽可能支持增量编译,这样可以节省一些编译的时间和资源,这个我们一会单独讲
1 2 3 override fun transform (transformInvocation: TransformInvocation ?) super .transform(transformInvocation)
transform 方法主要用于对输入的数据做检索操作,它是 Transform 的核心方法,方法的参数是 TransformInvocation,它是一个接口,提供了所有与输入输出相关的信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public interface TransformInvocation {getInputs () ;getReferencedInputs () ;getOutputProvider () ;boolean isIncremental () ;
1、isIncremental(): 当前 Transform 任务是否增量构建;
2、getInputs(): 获取 TransformInput 对象,它是消费型输入内容,对应于 Transform#getScopes() 定义的范围;
3、getReferencedInputs(): 获取 TransformInput 对象,它是引用型输入内容,对应于 Transform#getReferenceScope() 定义的内容范围;
4、getOutPutProvider(): TransformOutputProvider 是对输出文件的抽象。
输入内容 TransformInput 由两部分组成:
1、DirectoryInput 集合: 以源码方式参与构建的输入文件,包括完整的源码目录结构及其中的源码文件;
2、JarInput 集合: 以 jar 和 aar 依赖方式参与构建的输入文件,包含本地依赖和远程依赖。
输出内容 TransformOutputProvider 有两个主要功能:
1、deleteAll(): 当 Transform 运行在非增量构建模式时,需要删除上一次构建产生的所有中间文件,可以直接调用 deleteAll() 完成;
2、getContentLocation(): 获得指定范围+类型的输出目标路径。
到此为止,看起来 Transform 用起来也不难,但是,如果直接这样使用,会大大拖慢编译时间,为了解决这个问题,摸索了一段时间,也借鉴了Android 编译器中 Desugar 等几个 Transform 的实现,发现我们可以使用增量编译,并且上面 transform 方法遍历处理每个jar/class 的流程,其实可以并发处理,加上一般编译流程都是在 PC 上,所以我们可以尽量敲诈机器的资源。
上面也讲了,想要开启增量编译,只需要重写 Transform 的这个方法,返回 true 即可:
1 2 3 4 override fun isIncremental () Boolean {return true
嗯,没了,已经开启了😄。有这么简单就好了,言归正传:
1、如果不是增量编译,则会清空 output 目录,然后按照前面的方式,逐个处理 class/jar 。
2、如果是增量编译,则会检查每个文件的 Status,Status 分四种:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public enum Status {
根据不同的 Status 处理逻辑即可
3、实现增量编译后,我们最好也支持并发编译,并发编译的实现并不复杂,原理:对上面处理单个 class/jar 的逻辑进行并发处理,最后阻塞等待所有任务结束即可
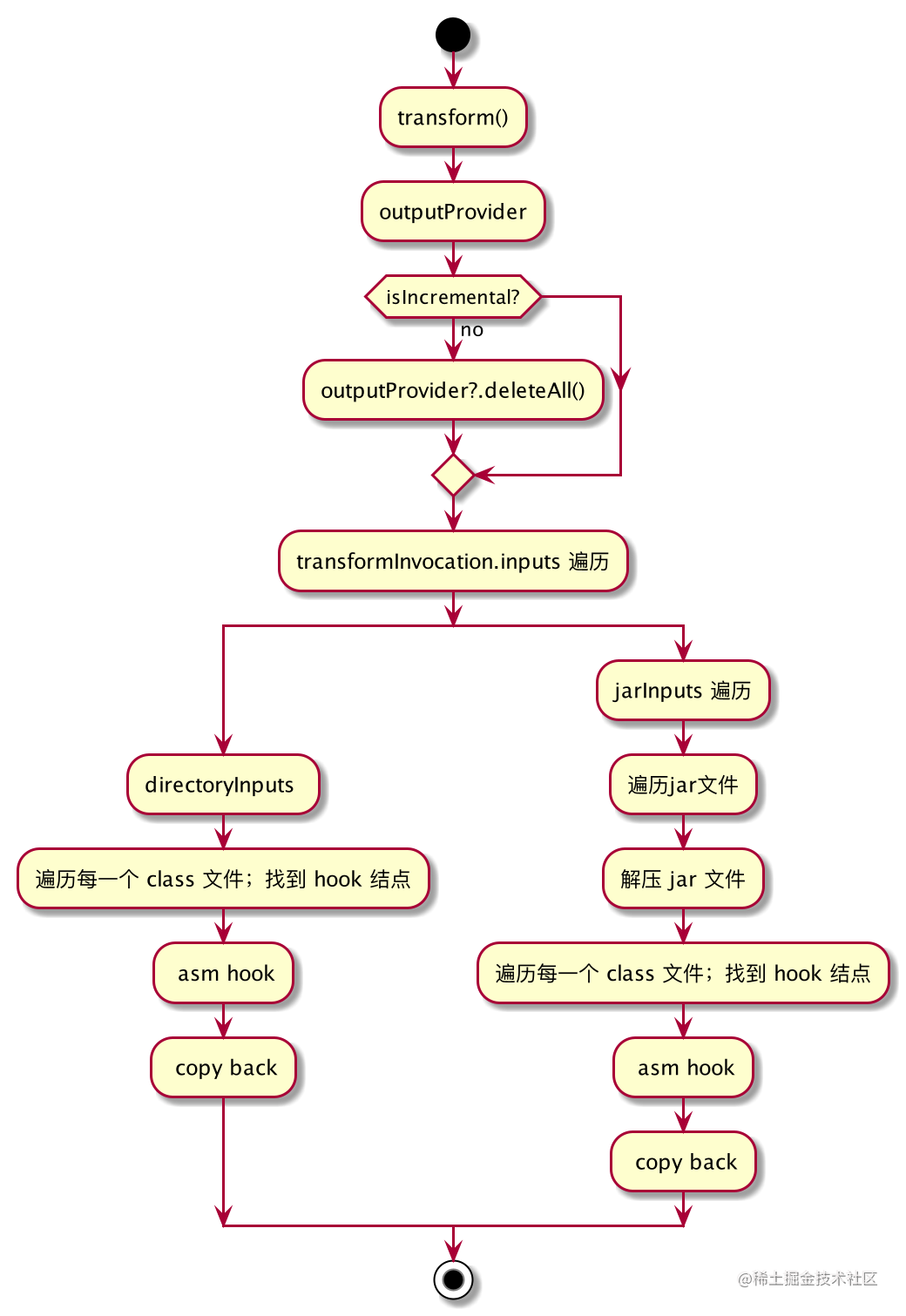
整个 Transform 的核心过程是有固定套路的,模板流程引入诗与远方 的一张图:
接下来,我们就按照上面这张图,来处理 Transform 的增量和并发,并封装一套通用的模版代码,下面模版写了详细的注释:
注意 :WaitableExecutor 在 AGP 7.0 中已经引用不到了,因此我们需要手动添加WaitableExecutor源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 abstract class BaseCustomTransform (private val enableLog: Boolean ) : Transform() {private var waitableExecutor: WaitableExecutor = WaitableExecutor.useGlobalSharedThreadPool()abstract fun provideFunction () Unit )?open fun classFilter (className: String ) override fun getInputTypes () return TransformManager.CONTENT_CLASSoverride fun getScopes () in QualifiedContent.Scope> {return TransformManager.SCOPE_FULL_PROJECToverride fun isIncremental () Boolean {return true override fun transform (transformInvocation: TransformInvocation ) super .transform(transformInvocation)"Transform start..." )val inputProvider = transformInvocation.inputsval outputProvider = transformInvocation.outputProviderval function = provideFunction()if (!transformInvocation.isIncremental) {for (input in inputProvider) {"Transform jarInputs start." )for (jarInput in input.jarInputs) {val inputJar = jarInput.fileval outputJar = outputProvider.getContentLocation(jarInput.name, jarInput.contentTypes, jarInput.scopes, Format.JAR)if (transformInvocation.isIncremental) {when (jarInput.status ?: Status.NOTCHANGED) {else {"Transform dirInput start." )for (dirInput in input.directoryInputs) {val inputDir = dirInput.fileval outputDir = outputProvider.getContentLocation(dirInput.name, dirInput.contentTypes, dirInput.scopes, Format.DIRECTORY)if (transformInvocation.isIncremental) {for ((inputFile, status) in dirInput.changedFiles) {val outputFile = concatOutputFilePath(outputDir, inputFile)when (status ?: Status.NOTCHANGED) {else {for (inputFile in FileUtils.getAllFiles(inputDir)) {val outputFile = concatOutputFilePath(outputDir, inputFile)if (classFilter(inputFile.name)) {else {true )"Transform end..." )private fun doTransformJar (inputJar: File , outputJar: File , function: ((InputStream , OutputStream ) -> Unit )?) var entry = zis.nextEntrywhile (entry != null && isValidZipEntryName(entry)) {if (!entry.isDirectory) {if (classFilter(entry.name)) {else {private fun doTransformFile (inputFile: File , outputFile: File , function: ((InputStream , OutputStream ) -> Unit )?) private fun applyFunction (input: InputStream , output: OutputStream , function: ((InputStream , OutputStream ) -> Unit )?) try {if (null != function) {else {catch (e: UncheckedIOException) {throw e.cause!!private fun concatOutputFilePath (outputDir: File , inputFile: File ) private fun log (logStr: String ) if (enableLog) {"$name - $logStr " )
上述模版给我们做了大量工作: Trasform 的输入文件遍历、加解压、增量,并发等,我们只需要专注字节码文件的修改即可
五、自定义模版使用 ok,接下来修改自定义 Gradle Transform 的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package com.dream.customtransformpluginimport java.io.InputStreamimport java.io.OutputStreamclass MyCustomTransform : BaseCustomTransform (true ) {override fun getName () return "ErdaiTransform" override fun provideFunction ()
是不是瞬间清爽了很多,发布一个新的插件版本,修改根 build.gradle 插件的版本,同步后重新运行 app,效果如下:
六、总结 本篇文章我们主要介绍了:
1、Gradle Transform 是什么?
简单的理解:我们可以自定义 Gradle Transform 修改字节码文件实现编译插桩
2、使用 Kotlin 编写自定义 Gradle Transform 的流程,注意和 Groovy 编写插件的区别
1、Kotlin 编写插件可直接写在 src/main/java 目录下
2、Groovy 编写插件需写在 src/main/groovy 目录下
3、介绍了 Transform 的数据流动和自定义 Gradle Transform 实现的相关 Api
4、介绍了 Transform 的增量与并发,并封装了一个模版,简化我们自定义 Gradle Transform 的使用
另外,本篇文章,我们只是讲了 Gradle Transform 简单使用,还没有做具体的插桩逻辑,因此前言中的问题暂时还解决不了
预知后事如何,请听下回分解
好了,本篇文章到这里就结束了,希望能给你带来帮助 🤝
Github Demo 地址 , 大家可以结合 demo 一起看,效果杠杠滴🍺
感谢你阅读这篇文章
参考和推荐 Gradle 系列(8)其实 Gradle Transform 就是个纸老虎
Gradle Transform + ASM 探索
Android Gradle 插件版本说明
你的点赞,评论,是对我巨大的鼓励!
欢迎关注我的公众号: sweetying
如果有问题 ,公众号内有加我微信的入口,在技术学习、个人成长的道路上,我们一起前进!