前言 引用 Gradle 官方一段对Gradle的介绍:Gradle is an open-source build automation tool focused on flexibility and performance. Gradle build scripts are written using a Groovy or Kotlin DSL.翻译过来就是:Gradle 是一个开源的自动化构建工具,专注于灵活性和性能。Gradle 构建脚本是使用 Groovy 或 Kotlin DSL 编写的。 之前官网的介绍是说 Gradle 是基于 Groovy 的 DSL,为啥现在又多了个 Kotlin 呢?因为 Gradle 从5.0开始,开始支持了 Kotlin DSL,现在已经发展到了6.8.3,因此我们可以使用 Groovy 或者 Kotlin 来编写 Gradle脚本。Kotlin 现作为 Android 第一开发语言,重要性不言而喻,作为一个 Android开发者,Kotlin 是必学的,后续我也会出个 Kotlin 系列文章。今天我们的重点是介绍一些 Gradle 的相关概念,以及对 Groovy 语言的学习
一、问题 我学习知识喜欢以问题为导向,这样可以让我明确学习的目的,提高学习效率,下面也是我在学习 Gradle 的过程中,由浅入深所产生的一些疑问,我们都知道,Android 应用是用 Gradle 构建的,在刚开发 Android 的时候我会想:
1、什么是自动化构建工具?
2、Gradle 是什么?
3、什么是 DSL?
4、什么是 Groovy?
5、Gradle 和 Groovy 有什么区别?
6、静态编程语言和动态编程语言有什么区别?
带着这些疑问,我们继续学习
1、自动化构建工具 在 Android 上的体现,简单的说就是自动化的编译、打包程序
在上大学学习 Java 那会,老师为了让我们深刻的体验撸码的魅力,都是通过文本直接敲代码的,敲完之后把扩展名改成.java后缀,然后通过javac命令编译,编译通过后,在执行java命令去运行,那么这种文件一多,我们每次都得手动去操作,效率会大大的降低,这个时候就出现了自动化编译工具,我们只需要在编译工具中,点击编译按钮,编译完成后,无需其他手动操作,程序就可以直接运行了,自动化编译工具就是最早的自动化构建工具。那么随着业务功能的不断扩展,我们的产品需要加入多媒体资源,需要打不同的渠道包发布到不同的渠道,那就必须依靠自动化构建工具,要能支持平台、需求等方面的差异、能添加自定义任务、专门的用来打包生成最终产品的一个程序、工具,这个就是自动化构建工具。自动化构建工具本质上还是一段代码程序。这就是自动化构建工具的一个发展历程,自动化构建工具在这个过程中不断的发展和优化
2、Gradle 是什么? 理解了自动化构建工具,那么理解 Gradle 就比较简单了,还是引用官方的那一段话:
Gradle 是一个开源的自动化构建工具,专注于灵活性和性能。Gradle 构建脚本是使用 Groovy 或 Kotlin DSL 编写的。
Gradle 是 Android 的默认构建工具,Android 项目这么多东西,既有我们自己写的 java、kotlin、C++、Dart 代码,也有系统自己的 java、C,C++ 代码,还有引入的第三方代码,还有多媒体资源,这么多代码、资源打包成 APK 文件肯定要有一个规范,干这个活的就是我们熟悉的 gradle 了,总而言之,Gradle就是一个帮我们打包 APK 的工具
3、什么是DSL? DSL英文全称:domain specific language ,中文翻译即领域特定语言,例如:HTML,XML等 DSL 语言
特点
解决特定领域的专有问题
它与系统编程语言走的是两个极端,系统编程语言是希望解决所有的问题,比如 Java 语言希望能做 Android 开发,又希望能做后台开发,它具有横向扩展的特性。而 DSL 具有纵向深入解决特定领域专有问题的特性。
总的来说,DSL 的核心思想 就是:“求专不求全,解决特定领域的问题”。
4、什么是 Groovy? Groovy 是基于 JVM 的脚本语言,它是基于Java扩展的动态语言
基于 JVM 的语言有很多种,如:Groovy,Kotlin,Java,Scala等等,他们都拥有一个共同的特性:最终都会编译生成 Java 字节码文件并在 JVM 上运行。
因为 Groovy 就是对 Java 的扩展,所以,我们可以用学习 Java 的方式去学习 Groovy 。 学习成本相对来说还是比较低的,即使开发过程中忘记 Groovy 语法,也可以用 Java 语法继续编码
5、Gradle 和 Groovy 有什么区别? Gradle 是基于 Groovy 的一种自动化构建工具,是运行在JVM上的一个程序,Groovy是基于JVM的一种语言,Gradle 和 Groovy 的关系就像 Android 和 Java 的关系一样
6、静态编程语言和动态编程语言有什么区别? 静态编程语言是在编译期就要确定变量的数据类型,而动态编程语言则是在运行期确定变量的数据类型。就像静态代理和动态代理一样,一个强调的是编译期,一个强调的是运行期,常见的静态编程语言有Java,Kotlin等等,动态编程语言有Groovy,Python等语言。
二、Groovy 开发环境搭建与工程创建 1、到官网下载JDK安装,并配置好 JDK 环境
2、到官网下载好 Groovy SDK,并解压到合适的位置
3、配置 Groovy 环境变量
4、到官网下载 IntelliJ IDEA 开发工具并安装
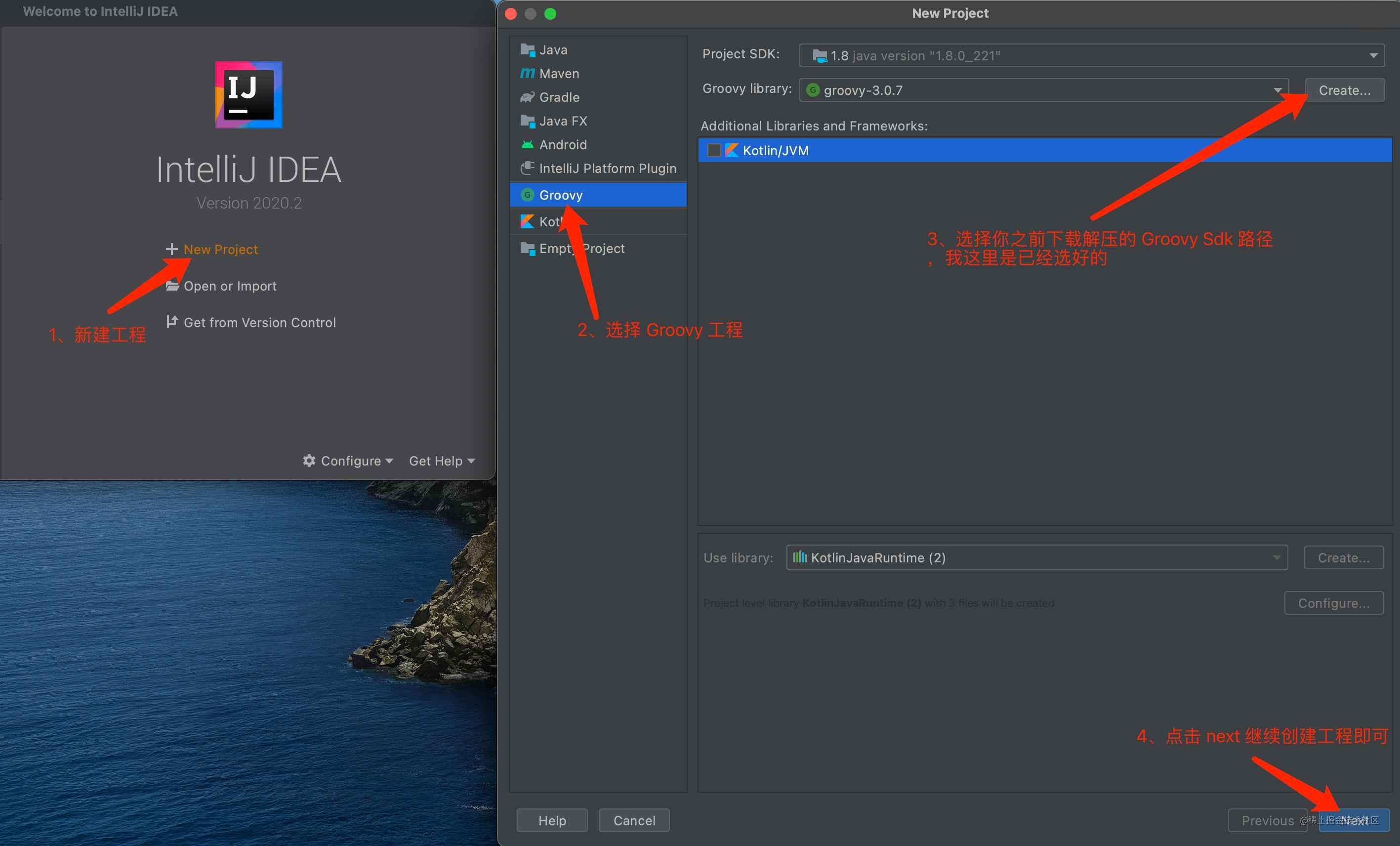
5、创建 Groovy 工程即可 完成了上述4个步骤,我们开始创建一个 Groovy 工程:
按照上述图片中步骤即可完成一个 Groovy 工程创建,下面就可以使用 IntelliJ IDEA 这个工具来学习 Groovy 了,我下面所有代码都是在 IntelliJ IDEA 上跑的
小技巧: 作为 Android 开发者,我们一般都是使用 AndroidStudio 进行开发的,但是 AndroidStudio 对于 Groovy 支持不是很友好,各种没有提示,涉及到闭包,你也不知道闭包的参数是啥?因此这个时候,你就可以使用 IntelliJ IDEA 先弄好,在复制过去,IntelliJ IDEA 对Groovy 的支持还是很友好的
三、Groovy 基础语法 再次强调 Groovy 是基于 java 扩展的动态语言,直接写 java 代码是没问题的,既然如此,Groovy 的优势在哪里呢?
在于 Groovy 提供了更加灵活简单的语法,大量的语法糖以及闭包特性可以让你用更少的代码来实现和 Java 同样的功能。比如解析xml文件,Groovy 就非常方便,只需要几行代码就能搞定,而如果用 Java 则需要几十行代码。
1、支持动态类型,使用 def 关键字来定义一个变量 在 Groovy 中可以使用 def 关键字定义一个变量,当然 Java 里面定义数据类型的方式,在 Groovy 中都能用
1 2 3 4 5 6 7 int age = 16 "erdai" def age = 16 def name = 'erdai'
2、不用写 ; 号 现在比较新的语言都不用写,如 Kotlin
1 2 def age = 16 def name = 'erdai'
3、没有基本数据类型了,全是引用类型 上面说到,定义一个变量使用 def 关键字,但是 Groovy 是基于 Java 扩展的,因此我们也可以使用 Java 里面的类型,如 Java 中8大基本类型:byte , short , int , long , float , double ,char,boolean
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 //定义8大基本类型
因此我们可以得出结论:Groovy中没有基本数据类型,全是引用类型,即使定义了基础类型,也会被转换成对应的包装类
4、方法变化 1、使用 def 关键字定义一个方法,方法不需要指定返回值类型,参数类型,方法体内的最后一行会自动作为返回值,而不需要return关键字
2、方法调用可以不写 () ,最好还是加上 () 的好,不然可读性不好
3、定义方法时,如果参数没有返回值类型,我们可以省略 def,使用 void 即可
4、实际上不管有没有返回值,Groovy 中返回的都是 Object 类型
5、类的构造方法,避免添加 def 关键字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def sum(a,b){def sum = sum(1 ,2 ) 3 void doSomething(param1, param2) {class MyClass {
5、字符串变化 在 Groovy 中有三种常用的字符串定义方式,如下所示:
这里先解释一下可扩展字符串的含义,可扩展字符串就是字符串里面可以引用变量,表达式等等
1 、单引号 ‘’ 定义的字符串为不可扩展字符串
2 、双引号 “” 定义的字符串为可扩展字符串,可扩展字符串里面可以使用 ${} 引用变量值,当 {} 里面只有一个变量,非表达式时,{}也可以去掉
3 、三引号 ‘’’ ‘’’ 定义的字符串为输出带格式的不可扩展字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def age = 16 def name = 'erdai' def str1 = 'hello ' + namedef str2 = "hello $name ${name + age}" def str3 = ''' \ hello name ''' 'str1类型: ' + str1.class println 'str1输出值: ' + str1'str2类型: ' + str2.class println 'str2输出值: ' + str2'str3类型: ' + str3.class println 'str3输出值: ' + str3class java .lang.Stringclass org .codehaus.groovy.runtime.GStringImplclass java .lang.String
从上面代码我们可以看到,str2 是 GStringImpl 类型的,而 str1 和 str3 是 String 类型的,那么这里我就会有个疑问,这两种类型在相互赋值的情况下是否需要强转呢?我们做个实验在测试下:
1 2 3 4 5 6 7 8 'str4类型: ' + str4.class println 'str4输出值: ' + str4class java .lang.String
因此我们可以得出结论:编码的过程中,不需要特别关注 String 和 GString 的区别,编译器会帮助我们自动转换类型 。
6. 不用写 get 和 set 方法 1、在我们创建属性的时候,Groovy会帮我们自动创建 get 和 set 方法
2、当我们只定义了一个属性的 get 方法,而没有定义这个属性,默认这个属性只读
3、我们在使⽤对象 object.field 来获取值或者使用 object.field = value 来赋值的时候,实际上会自动转而调⽤ object.getField() 和 object.setField(value) 方法,如果我们不想调用这个特殊的 get 方法时则可以使用 .@ 直接域访问操作符访问属性本身
我们来模拟1,2,3这三种情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class People {def people = new People ()'erdai' 19 "姓名: $people.name 年龄: $people.age" 19 class People {getAge () {12 def people = new People ()'erdai' 19 "姓名: $people.name 年龄: $people.age" for class: variable.Peopleclass People {getName () {"My name is $name" def people = new People (name: 'erdai666' )19 def myName = people.@name "姓名: $people.name 年龄: $people.age" 19
7、Class 是一等公民,所有的 Class 类型可以省略 .Class 1 2 3 4 5 6 7 8 9 10 11 12 13 class Test { def testClass(myClass){class )
8、== 和 equals 在 Groovy 中,== 就相当于 Java 的 equals,如果需要比较两个对象是否是同一个,需要使用 .is()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class People {def namedef agedef people1 = new People(name: 'erdai666' )def people2 = new People(name: 'erdai666' )"people1.name == people2.name is: " + (people1.name == people2.name))"people1 is people2 is: " + people1.is(people2))is: true is: false
9、使用 assert 来设置断言,当断言的条件为 false 时,程序将会抛出异常 1 2 3 4 5 6 assert 2 ** 4 == 15 Caught: Assertion failed: assert 2 ** 4 == 15 16 false
10、支持 ** 次方运算符 11、简洁的三元表达式 1 2 3 4 5 null ? obj : "" ""
12、简洁的非空判断 1 2 3 4 5 6 7 8 9 10 11 12 if (obj != null ){if (obj.group != null ){if (obj.group.artifact != null ){
13、强大的 Switch 在 Groovy 中,switch 方法变得更加灵活,强大,可以同时支持更多的参数类型,比在 Java 中增强了很多
1 2 3 4 5 6 7 8 9 10 11 def result = 'erdai666' switch (result){case [1 ,2 ,'erdai666' ]:"匹配到了result" break default: 'default' break
14、判断是否为 null 和 非运算符 在 Groovy 中,所有类型都能转成布尔值,比如 null 就相当于0或者相当于false,其他则相当于true
1 2 3 4 5 6 7 8 9 10 11 12 if (name != null && name.length > 0 ) {if (name){assert (!'erdai' ) = false
15、可以使用 Number 类去替代 float、double 等类型,省去考虑精度的麻烦 16、默认是 public 权限 默认情况下,Groovy 的 class 和 方法都是 public 权限,所以我们可以省略 public 关键字,除非我们想使用 private 修饰符
1 2 3 class Server { "a server" }
17、使用命名的参数初始化和默认的构造器 Groovy中,我们在创建一个对象实例的时候,可以直接在构造方法中通过 key value 的形式给属性赋值,而不需要去写构造方法,说的有点抽象,上代码感受一下:
1 2 3 4 5 6 7 8 9 10 11 class People {def namedef agedef people1 = new People()def people1 = new People(age: 15 )def people2 = new People(name: 'erdai' )def people3 = new People(age: 15 ,name: 'erdai' )
18、使用 with 函数操作同一个对象的多个属性和方法 with 函数接收一个闭包,闭包下面会讲,闭包的参数就是当前调用的对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class People {def namedef agevoid running(){'跑步' def people = new People()"erdai" 19 "$name $age" 19
19、异常捕获 如果你实在不想关心 try 块里抛出何种异常,你可以简单的捕获所有异常,并且可以省略异常类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 try {catch (Exception e) {try {catch (any) {
上面 Groovy 的写法其实就是省略了参数类型,实际上 any 的参数类型也是 Exception, 并不包括 Throwable ,如果你想捕获所有的异常,你可以明确捕获异常的参数类型
四、Groovy 闭包 在 Groovy 中,闭包非常的重要,因此单独用一个模块来讲
1、闭包定义 引用 Groovy 官方对闭包的定义:A closure in Groovy is an open, anonymous, block of code that can take arguments, return a value and be assigned to a variable. 翻译过来就是:Groovy 中的闭包是一个开放的、匿名的代码块,它可以接受参数、返回值并将值赋给变量。 通俗的讲,闭包可以作为方法的参数和返回值,也可以作为一个变量而存在,闭包本质上就是一段代码块,下面我们就由浅入深的来学习闭包
2、闭包声明 1、闭包基本的语法结构:外面一对大括号,接着是申明参数,参数类型可省略,在是一个 -> 箭头号,最后就是闭包体里面的内容
2、闭包也可以不定义参数,如果闭包没定义参数的话,则隐含有一个参数,这个参数名字叫 it
1 2 3 4 5 6 7 8 9
3、闭包调用 1、闭包可以通过 .call 方法来调用
2、闭包可以直接用括号+参数来调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def closure = { params1,params2 ->def result1 = closure('erdai ' ,'666' )def result2 = closure.call('erdai ' ,'777' )666 777 def closure1 = {'无定义参数闭包' )
4、闭包进阶 1)、闭包中的关键变量 每个闭包中都含有 this、owner 和 delegate 这三个内置对象,那么这三个三个内置对象有啥区别呢?我们用代码去验证一下
注意 :
1、getThisObject() 方法 和 thisObject 属性等同于 this
2、getOwner() 方法 等同于 owner
3、getDelegate() 方法 等同于 delegate
这些去看闭包的源码你就会有深刻的体会
1、我们在 GroovyGrammar.groovy 这个脚本类中定义一个闭包打印这三者的值看一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 def outerClosure = {"this: " + this "owner: " + owner"delegate: " + delegatethis: variable.GroovyGrammar@39 dcf4b0owner: variable.GroovyGrammar@39 dcf4b0delegate: variable.GroovyGrammar@39 dcf4b0
2、我们在这个 GroovyGrammar.groovy 这个脚本类中定义一个类,类中定义一个闭包,打印看下结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class OuterClass {def outerClosure = {"this: " + this "owner: " + owner"delegate: " + delegatedef outerClass = new OuterClass()this: variable.OuterClass@1992 eaf4owner: variable.OuterClass@1992 eaf4delegate: variable.OuterClass@1992 eaf4
3、我们在 GroovyGrammar.groovy 这个脚本类中,定义一个闭包,闭包中在定义一个闭包,打印看下结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def outerClosure = {def innerClosure = {"this: " + this "owner: " + owner"delegate: " + delegate64 beebb7this: variable.GroovyGrammar@5 b58ed3cowner: variable.GroovyGrammar$_run_closure4@64 beebb7delegate: variable.GroovyGrammar$_run_closure4@64 beebb7
我们梳理一下上面的三种情况:
1、闭包定义在GroovyGrammar.groovy 这个脚本类中 this owner delegate 就指向这个脚本类对象
2、我在这个脚本类中创建了一个 OuterClass 类,并在他里面定义了一个闭包,那么此时 this owner delegate 就指向了 OuterClass 这个类对象
3、我在 GroovyGrammar.groovy 这个脚本类中定义了一个闭包,闭包中又定义了一个闭包,this 指向了当前GroovyGrammar这个脚本类对象, owner 和 delegate 都指向了 outerClosure 闭包对象
因此我们可以得到结论:
1、this 永远指向定义该闭包最近的类对象,就近原则,定义闭包时,哪个类离的最近就指向哪个,我这里的离得近是指定义闭包的这个类,包含内部类
2、owner 永远指向定义该闭包的类对象或者闭包对象,顾名思义,闭包只能定义在类中或者闭包中
3、delegate 和 owner 是一样的,我们在闭包的源码中可以看到,owner 会把自己的值赋给 delegate,但同时 delegate 也可以赋其他值
注意:在我们使用 this , owner , 和 delegate 的时候, this 和 owner 默认是只读的,我们外部修改不了它,这点在源码中也有体现,但是可以对 delegate 进行操作
2)、闭包委托策略 下面我们就来对修改闭包的 delegate 进行实操:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Banana {def nameclass Orange {def namedef banana = new Orange(name: '香蕉' )def orange = new Orange(name: '橘子' )def closure = {Caught: groovy.lang.MissingPropertyException: No such property: name for class: variable.GroovyGrammar
我们来分析下报错的原因原因,分析之前我们要明白一个知识点:
闭包的默认委托策略是 OWNER_FIRST,也就是闭包会先从 owner 上寻找属性或方法,找不到则在 delegate 上寻找
1、closure 这个闭包是生明在 GroovyGrammar 这个脚本类当中
2、根据我们之前学的知识,在不改变 delegate 的情况下 delegate 和 owner 是一样的,都会指向 GroovyGrammar 这个脚本类对象
3、GroovyGrammar 这个脚本类对象,根据闭包默认委托策略,找不到 name 这个属性
因此报错了,知道了报错原因,那我们就修改一下闭包的 delegate , 还是上面那段代码,添加如下这句代码:
1 2 3 4
此时闭包的 delegate 指向了 orange ,因此会打印 orange 这个对象的 name ,那么我们把 closure 的 delegate 改为 banana,肯定就会打印香蕉了
1 2 3 4
3)、深入闭包委托策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class ClosureDepth {def str1 = 'erdai666' def outerClosure = {def str2 = 'erdai777' def innerClosure = {def closureDepth = new ClosureDepth()
上面代码注释写的很清楚,现在我们来重点分析下分析1和分析2处的打印值:
分析1:
分析1处打印了 str1 , 它处于 outerClosure 这个闭包中,此时 outerClosure 这个闭包的 owner , delegate 都指向了 ClosureDepth 这个类对象,因此 ClosureDepth 这个类对象的属性和方法我们就都能调用到,因此分析1处会打印 erdai666
分析2:
分析2处打印了 str1和 str2,它处于 innerClosure 这个闭包中,此时 innerClosure 这个闭包的 owner 和 delegate 会指向 outerClosure 这个闭包对象,我们会发现 outerClosure 有 str2 这个属性,但是并没有 str1 这个属性,因此 outerClosure 这个闭包会向它的 owner 去寻找,因此会找到 ClosureDepth 这个类对象的 str1 属性,因此打印的 str1 是ClosureDepth 这个类对象中的属性,打印的 str2 是outerClosure 这个闭包中的属性,所以分析2处的打印结果分别是 erdai666 erdai777
上面的例子中没有显式的给 delegate 设置一个接收者,但是无论哪层闭包都能成功访问到 str1、str2 值,这是因为默认的解析委托策略在发挥作用,Groovy 闭包的委托策略有如下几种:
OWNER_FIRST :默认策略,首先从 owner 上寻找属性或方法,找不到则在 delegate 上寻找DELEGATE_FIRST :和上面相反,首先从 delegate 上寻找属性或者方法,找不到则在 owner 上寻找OWNER_ONLY :只在 owner 上寻找,delegate 被忽略DELEGATE_ONLY :和上面相反,只在 delegate 上寻找,owner 被忽略TO_SELF :高级选项,让开发者自定义策略,必须要自定义实现一个 Closure 类,一般我们这种玩家用不到
下面我们就来修改一下闭包的委托策略,加深理解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class People1 {def name = '我是People1' def action(){'吃饭' def closure = {class People2 {def name = '我是People2' def action(){'睡觉' def people1 = new People1()def people2 = new People2()
what? 这是啥情况,我不是修改了 delegate 为 people2 了,怎么打印结果还是 people1 的?那是因为我们忽略了一个点,没有修改闭包委托策略,他默认是 OWNER_FIRST ,因此我们修改一下就好了,还是上面这段代码,添加一句代码如下:
1 2 3 4 people1.closure.resolveStrategy = Closure.DELEGATE_FIRST
到这里,相信你对闭包了解的差不多了,下面我们在看下闭包的源码就完美了
4)、闭包 Closure 类源码 仅贴出关键源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public abstract class Closure <V> extends GroovyObjectSupport implements Cloneable , Runnable, GroovyCallable<V>, Serializable {public static final int OWNER_FIRST = 0 ;public static final int DELEGATE_FIRST = 1 ;public static final int OWNER_ONLY = 2 ;public static final int DELEGATE_ONLY = 3 ;public static final int TO_SELF = 4 ;private Object delegate;private Object owner;private Object thisObject;private int resolveStrategy;public Closure(Object owner, Object thisObject) {this .resolveStrategy = 0 ;this .owner = owner;this .delegate = owner;this .thisObject = thisObject;this .getClass());this .parameterTypes = cachedClass.getParameterTypes();this .maximumNumberOfParameters = cachedClass.getMaximumNumberOfParameters();public Object getThisObject() {return this .thisObject;public Object getOwner() {return this .owner;public Object getDelegate() {return this .delegate;public void setDelegate(Object delegate) {this .delegate = delegate;public void setResolveStrategy(int resolveStrategy) {this .resolveStrategy = resolveStrategy;public int getResolveStrategy() {return resolveStrategy;
到这里闭包相关的知识点就都讲完了,但是,但是,但是,重要的事情说三遍:我们使用闭包的时候,如何去确定闭包的参数呢? ,这个真的很蛋疼,作为 Android 开发者,在使用 AndroidStudio 进行 Gradle 脚本编写的时候,真的是非常不友好,上面我讲了可以使用一个小技巧去解决这个问题,但是这种情况是在你知道要使用一个 Api 的情况下,比如你知道 Map 的 each 方法可以遍历,但是你不知道参数,这个时候就可以去使用。那如果你连 Api 都不知道,那就更加不知道闭包的参数了,因此要解决这种情况,我们就必须去查阅 Groovy 官方文档:
http://www.groovy-lang.org/api.html
http://docs.groovy-lang.org/latest/html/groovy-jdk/index-all.html
五、Groovy数据结构 通过这个模块的学习,我会结合具体的例子来说明如何查阅文档来确定闭包中的参数,在讲 Map 的时候我会讲到
Groovy 常用的数据结构有如下 四种:
1)、数组
2)、List
3)、Map
4)、Range
1、数组 在 Groovy 中使用 [ ] 表示的是一个 List 集合,如果要定义 Array 数组,我们就必须强制指定为一个数组的类型
1 2 3 4 5 "Java" , "Groovy" , "Android" ]def groovyArray = ["Java" , "Groovy" , "Android" ] as String[]
2、List 1)、列表集合定义 1、List 即列表集合,对应 Java 中的 List 接口,一般用 ArrayList 作为真正的实现类
2、定义一个列表集合的方式有点像 Java 中定义数组一样
3、集合元素可以接收任意的数据类型
1 2 3 4 5 6 7 8 9 def list1 = [1 ,2 ,3 ]class class java .util.ArrayListdef list2 = ['erdai666' , 1 , true ]
那么问题来了,如果我想定义一个 LinkedList 集合,要怎么做呢?有两种方式:
1、通过 Java 的强类型方式去定义
2、通过 as 关键字来指定
1 2 3 4 5 4 , 5 , 6 ]def list4 = [1 , 2 , 3 ] as LinkedList
2)、列表集合增删改查 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def list = [1 ,2 ,3 ]20 )20 )20 0 )0 ] = 100
列表集合 Api 挺多的,对于一些其他Api,使用到的时候自行查阅文档就好了,我会在下面讲 Map 的时候演示查阅 Api 文档确定闭包的参数
3、Map 1)、定义 1、Map 表示键-值表,其底层对应 Java 中的 LinkedHashMap
2、Map 变量由[:]定义,冒号左边是 key,右边是 Value。key 必须是字符串,value 可以是任何对象
3、Map 的 key 可以用 ‘’ 或 “” 或 ‘’’ ‘’’包起来,也可以不用引号包起来
1 def map = [a: 1 , 'b' : true , "c" : "Groovy" , '''d''' : '''ddd''' ]
2)、Map 常用操作 这里列举一些 Map 的常用操作,一些其他的 Api 使用到的时候自行查阅文档就好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 'b' ]'c' )1 true 'key' ,'value' )'key' ] = "value"
3)、Map 遍历,演示查阅官方文档 现在我要去遍历 map 中的元素,但是我不知道它的 Api 是啥,那这个时候就要去查官方 Api 文档了:
http://docs.groovy-lang.org/latest/html/groovy-jdk/java/util/Map.html
我们查到 Map 有 each 和 eachWithIndex 这两个 Api 可以去执行遍历操作,接着点进去看一眼
通过官方文档我们可以发现: each 和 eachWithIndex 的闭包参数还是不确定的,如果我们使用 each 方法,如果传递给闭包是一个参数,那么它就把 entry 作为参数,如果我们传递给闭包是两个参数,那么它就把 key 和 value 作为参数,eachWithIndex 比 each 多了个 index 下标而已.
那么我们现在就使用以下这两个 Api :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def map = [a: 1 , 'b' : true , "c" : "Groovy" , '''d''' : '''ddd''' ]"$it.key $it.value \t" "$key $value \t" "$entry.key $entry.value $index \t" "$key $value $index \t" 1 b true c Groovy d ddd 1 b true c Groovy d ddd 1 0 b true 1 c Groovy 2 d ddd 3 1 0 b true 1 c Groovy 2 d ddd 3
4、Range Range 表示范围,它其实是 List 的一种拓展。其由 begin 值 + 两个点 + end 值表示。如果不想包含最后一个元素,则 begin 值 + 两个点 + < + end 表示。我们可以通过 aRange.from 与 aRange.to 来获对应的边界元素 ,实际操作感受一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def range = 1. .10 " " 1 2 3 4 5 6 7 8 9 10 def range1 = 1. .<10 " " 1 2 3 4 5 6 7 8 9 "$range1.from $range1.to" 1 9
六、Groovy 文件处理 1、IO 一些 IO 常用的 Api 操作,我们直接上代码看效果,代码会写上清晰的注释:
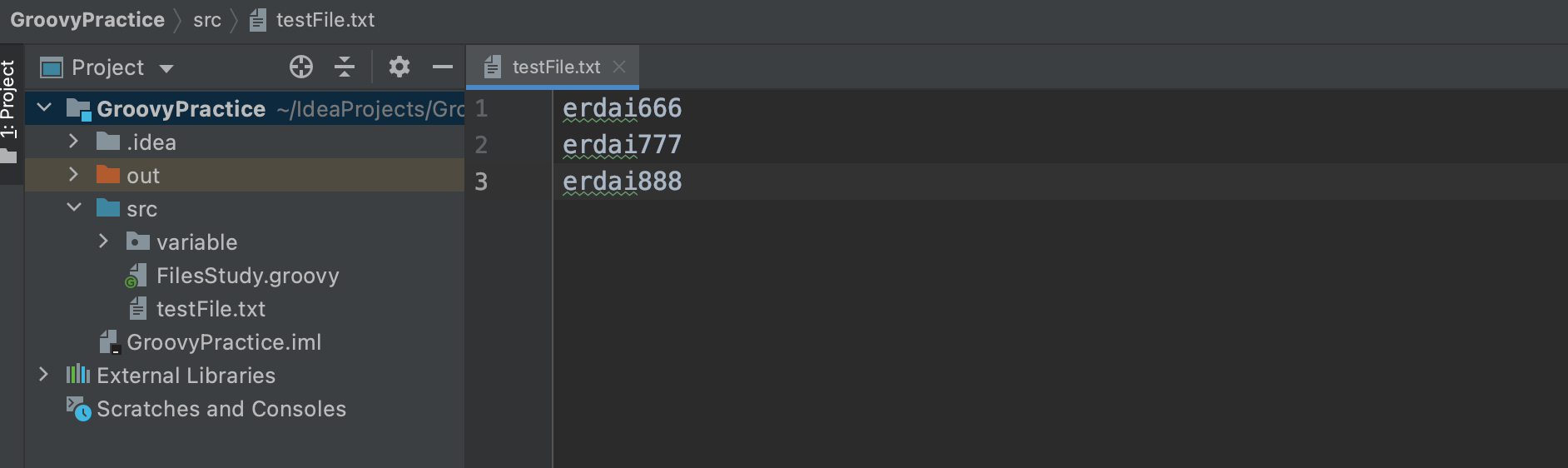
准备工作:我在当前脚本文件的同级目录下创建一个 testFile.txt 文件,里面随便先写入一些字符串,如下图:
下面我们开始来操作这个文件,为了闭包的可读性,我会在闭包上加上类型和参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def file = new File('testFile.txt' )"erdai999" .getBytes())'erdai999' )def targetFile = new File('testFile1.txt' )"\r\n" )
2、XML 文件操作 1)、解析 XML 文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def xml = ''' <response> <value> <books id="1" classification="android"> <book available="14" id="2"> <title>第一行代码</title> <author id="2">郭霖</author> </book> <book available="13" id="3"> <title>Android开发艺术探索</title> <author id="3">任玉刚</author> </book> </books> </value> </response> ''' def xmlSlurper = new XmlSlurper()def response = xmlSlurper.parseText(xml)0 ].book[0 ].title.text()0 ].book[0 ].author.text()def str1 = response.depthFirst().findAll { book ->return book.author == '郭霖' def str2 = response.value.books.children().findAll{ node ->'book' && node.@id == '2' "$node.title $node.author"
2)、生成 XML 文件 上面我们使用 XmlSlurper 这个类解析了 XML,现在我们借助 MarkupBuilder 来生成 XML ,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 def sw = new StringWriter()def xmlBuilder = new MarkupBuilder(sw)id: '1' ,classification: 'android' ){available: '14' ,id: '2' ){'第一行代码' )id: '2' ,'郭霖' )available: '13' ,id: '3' ){'Android开发艺术探索' )id: '3' ,'任玉刚' )class Response {def value = new Value()class Value {def books = new Books(id: '1' , classification: 'android' )class Books {def iddef classificationdef book = [new Book(available: '14' , id: '2' , title: '第一行代码' , authorId: 2 , author: '郭霖' ),new Book(available: '13' , id: '3' , title: 'Android开发艺术探索' , authorId: 3 , author: '任玉刚' )]class Book {def availabledef iddef titledef authorIddef authordef response = new Response()id: response.value.books.id,classification: response.value.books.classification){def book1 = itavailable: it.available,id: it.id){authorId: book1.authorId,book1.author)
3、Json 解析 Json解析主要是通过 JsonSlurper 这个类实现的,这样我们在写插件的时候就不需要额外引入第三方的 Json 解析库了,其示例代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def response = getNetWorkData("https://www.wanandroid.com/banner/json" )0 ].desc0 ].imagePathdef getNetWorkData(String url){def connect = new URL(url).openConnection()"GET" )def response = connect.content.textdef jsonSlurper = new JsonSlurper()https:
7、总结 在本篇文章中,我们主要介绍了以下几个部分:
1、一些关于 Gradle ,Groovy 的问题
2、搭建 Groovy 开发环境,创建一个 Groovy 工程
3、讲解了 Groovy 的一些基础语法
4、对闭包进行了深入的讲解
5、讲解了 Groovy 中的数据结构和常用 Api 使用,并以 Map 举例,查阅官方文档去确定 Api 的使用和闭包的参数
6、讲解了 Groovy 文件相关的处理
学习了 Groovy ,对于我们后续自定义 Gradle 插件迈出了关键的一步。其次如果你学习过 Kotlin ,你会发现,它们的语法非常的类似,因此对于后续学习 Kotlin 我们也可以快速去上手。
参考和推荐 深度探索 Gradle 自动化构建技术(二、Groovy 筑基篇
Gradle 爬坑指南 – 概念初解、Grovvy 语法、常见 API
Groovy 本质初探及闭包特性原理总结
Gradle从入门到实战 - Groovy基础
慕课网之Gradle3.0自动化项目构建技术精讲+实战
你的点赞,评论,是对我巨大的鼓励!
欢迎关注我的公众号: sweetying
如果有问题 ,公众号内有加我微信的入口,在技术学习、个人成长的道路上,我们一起前进!